let input = ... let output = input |> A |> B |> C |> D
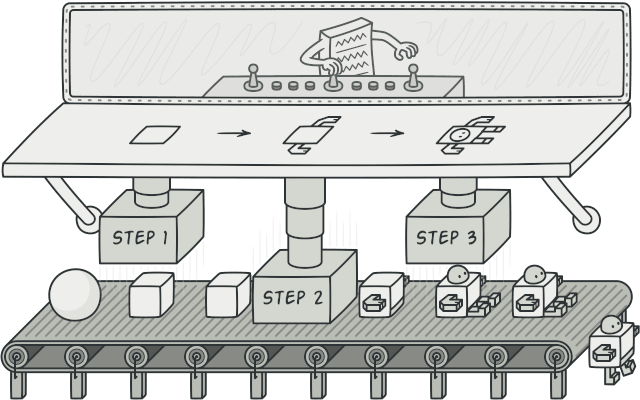
在现实中,这表示着 “pipeline 上有 A B C D 四个步骤”。再具体一点,它们可能各自完成:代码克隆、编译、测试、发布。
但是一般的流水线设计会复杂一些,流水线不仅拥有 “单方向 / 形式” 的输入,即:
1 2 3
a b c d | | | | input => A -> B -> C -> D => output
这个过程可以表示为:
流水线不仅以前节点的输出为输入,还可能有各节点特别的输入。在现实生活中,这表现为 “各步骤除自动接受 pipeline 上流动的数据之外,有些额外配置需要提供人工输入”。再具体一点,很可能上图中 a 表示着 A 需要克隆的 repo URL;c 表示着 C 是否需要提供 coverage report。
classMyVisitorextendsASTVisitor{ var types = Array.empty[TypeDeclaration] var enums = Array.empty[EnumDeclaration] overridedefvisit(node: TypeDeclaration): Boolean = if node.isMemberTypeDeclaration || node.isPackageMemberTypeDeclaration then types = types :+ node end if super.visit(node)
overridedefvisit(node: EnumDeclaration): Boolean = if node.isMemberTypeDeclaration || node.isPackageMemberTypeDeclaration then enums = enums :+ node end if super.visit(node) }
但是我要筛选出 cu 中满足我要求的部分。(比如 cu 必须定义 package;cu 的 types 必须不为空等等)所以一开始我就写了具有这些代码的函数: