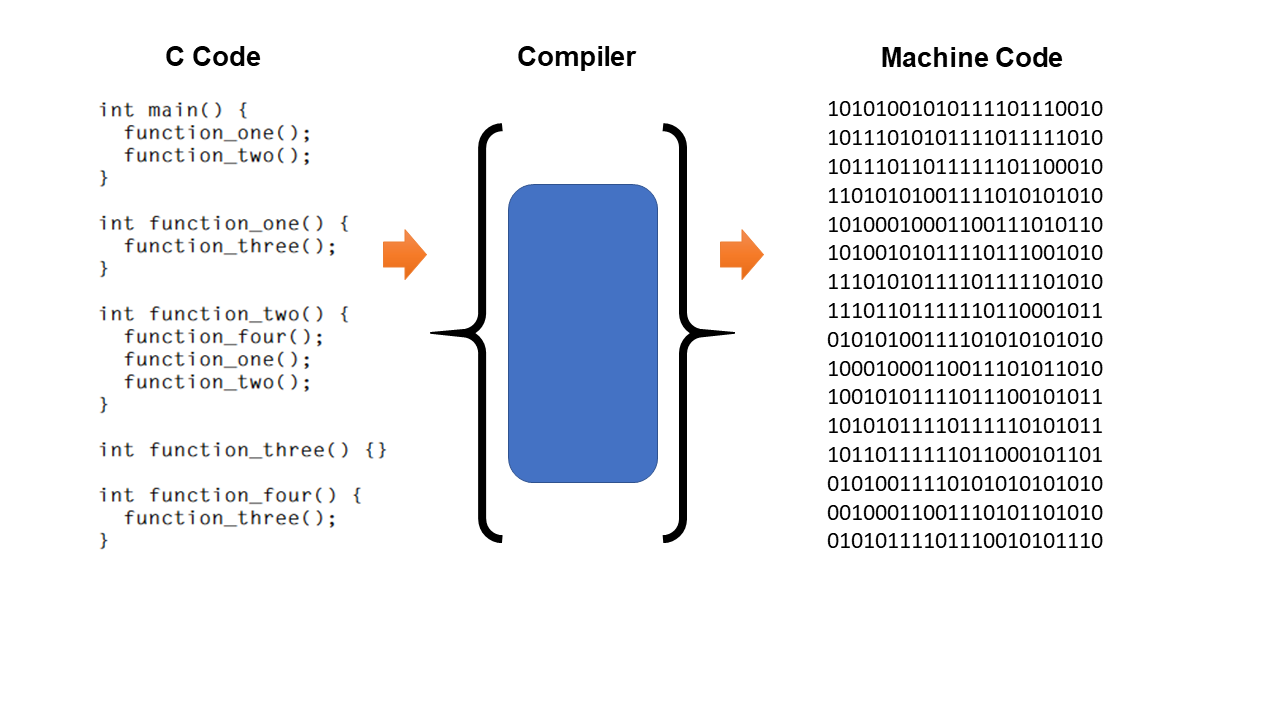
一、为啥学的 x86 汇编不能两个操作数都是存储器啊
1. 你猜为什么我这么口嗨汇编
当时就觉得很不方便,非得先把存储器里面的东西放到寄存器来,然后再通过 “寄存器-存储器” 的指令要求运算。还一度怀疑设计 汇编语言 的前辈们脑子出了问题。
2. 为什么我会这么口嗨汇编啊
我是不知道现在市面上这些 ISA 都是怎么一个过程设计出来的。但推测的话,ISA 的设计需要考虑当时的科学技术,比如存储器速度、存储容量之类的。内存宝贵,就用变长指令压缩指令在存储器中的所占空间;内存便宜了,就用定长指令方便开发者。ISA 的 A 和其他很多地方的 A 都差不多,不是什么一成不变的东西。
毕竟这是汇编语言,是和 “机器” 高度关联的。这个关联不是说 CPU 的设计指导了 ISA 的设计,也不是说 ISA 一定都是设计好了再去写 CPU。我猜应该是一个互相选择的问题,不存在哪一方有绝对的主导权。
但说这么多,设计 ISA 肯定得考虑硬件啊。假设要求 ADD op1, op2 这个指令得一个时钟周期做完,但是现在存储器就一块,存储器的数据总线也就一条,op1 和 op2 怎么可能都是存储器里的东西嘛?
要是有一种架构,它就是有两块存储器,每一块还都有独立的数据总线,肯定就可以做 ADD mem1, mem2 了啊。当然也还有另外一种极端,“LOAD-STORE” 架构全部都在寄存器里面运算,从存储器 LOAD 到寄存器,再把寄存器里面算好的 STORE 会存储器。
二、流水线明明用了那么多时钟周期,为啥还快了
1. 你猜为什么我觉得流水线慢
隔壁写的 CPU,单周期也是 100 ns,多周期也还是一个时钟周期 100 ns。那凭啥还多周期,这一个指令岂不是执行了 500 ns?并且流水线还得考虑什么分支预测,万一预测错了,岂不是全部白给?
2. 为什么我会觉得流水线慢啊
我这不多少沾点?单周期 100 ns,按 MIPS 经典的 5-Stage-Pipeline,每一个 Stage 岂不是可以 20 ns?单个指令执行时间还是 100 ns,但是高效利用 CPU 内剩余部件了。这不和超长指令字一个思想?那为啥我觉得 VLIW 好,就不觉得 Pipeline 合理?
哪怕 x-Stage-Pipeline 达不到 x 的加速比,那不也是快了?
三、磁盘应该很快就坏了才对吧,磁头会对盘片造成很大伤害吧
1. 你猜为什么我觉得磁头会对盘片造成很大伤害
还用问?一下下撞的。更恐怖的是,如果驱动臂坏了,抬不起来,那岂不是把磁盘刮花了。
2. 为什么我会觉得磁头会对盘片造成很大伤害啊
究竟是什么给了我 “磁头一定要碰到盘面的错觉”?
那不是磁盘吗?如果是靠表面凹凸存储数据的(肯定不可能哈,如果这样那还能写入了吗),那为什么要用磁性介质?就是要通过 balabala(我也不懂)的物理手段,让磁盘上的数据传到磁头上来呀。
但这不是我需要关心的,我只关心我自己。
(计组的复习未完,所以必有后续)