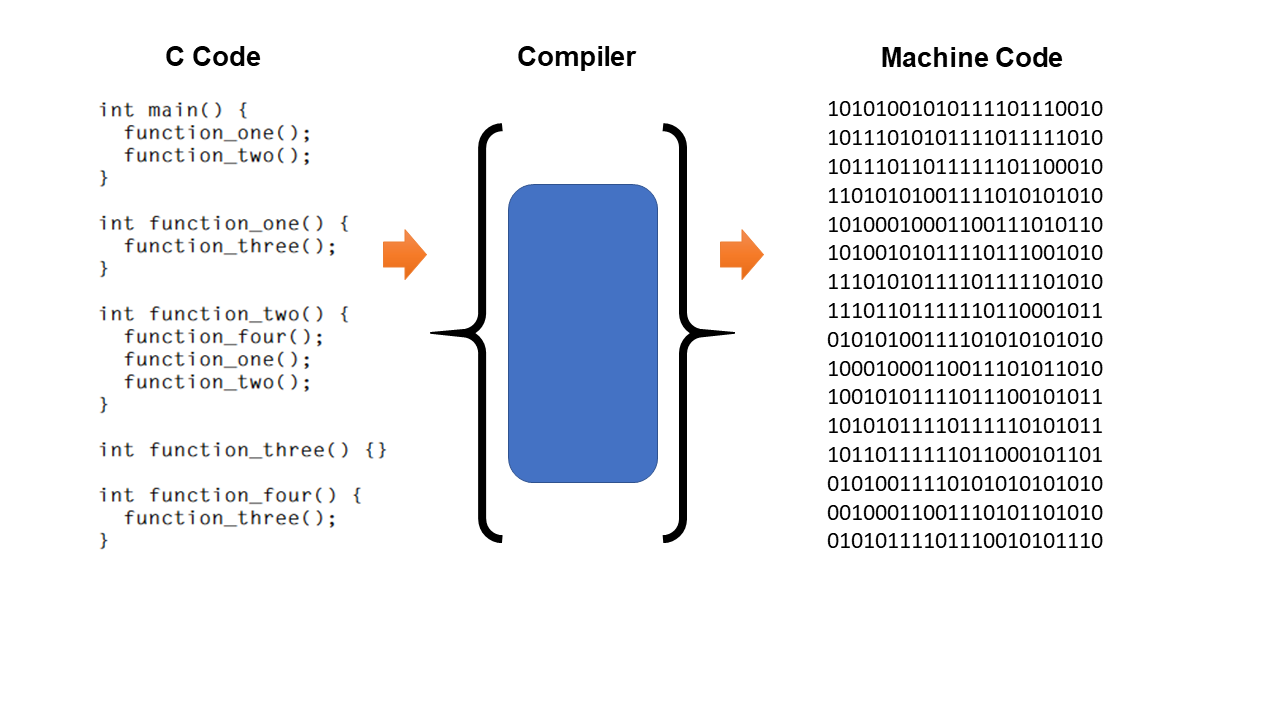
问题背景

众所周知,同济大学总共有 4 个校区:
- 四平路校区
- 彰武路校区
- 沪北校区
- 南校区
实际上,同济大学还有一个不为人知的校区,我们暂且称其为 J 区。
J 区 并不在上海,与其他 4 个校区地理距离过远,但是 J 区 确乎有一定量的学生,为方便存储、管理这部分学生的数据,J 区 也建立了一套数据库系统。(废话)
由于 J 区 战略地位过于靠后, J 区 学生的个人信息不受到主校区重视,以至于 J 区 数据库每天中午 12 点才与四平路校区的数据库同步一次。
出现问题
Mr.Tan 是我校电信学院的老师,敏锐地捕捉到了 “校园卡数据并非存放在一个数据库中,且二库同步周期过长” 这件事,于是进行了以下实验:
- 早上 6:00 于四平路校区学苑饮食广场,拿余额为 200 元的教师卡购买 10 碗炸酱土豆卤蛋牛肉面,消费 100 元。
- 早上 7:00 撑得不行的 Mr.Tan,于四平路校区西南门登上校车。
- 上午 9:00 在车上补完觉的 Mr.Tan 来到 J 区。
- 上午 11:35 Mr.Tan 上完 “安全体系结构”,来到秋谷苑三楼,点了 4 碗一点油水都没有的过水面,再次消费 100 元。
- 中午 12:00,校区间数据开始同步,Mr.Tan 教师卡余额为 100 元。
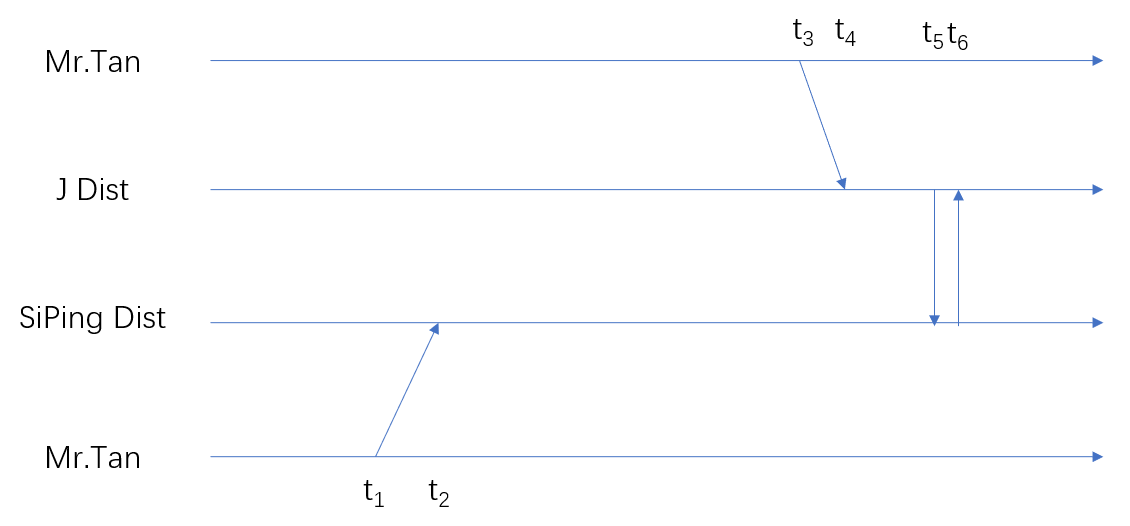
(以上过程纯属杜撰,没有巧合)
其实
据老师所述,我校两校区间的数据同步时,遵照某些预定义的默契。比如 校园卡余额 这一栏,则是:
1 | import datetime |
如此扯淡的逻辑,根本没有写出来的必要吧?
在 Mr.Tan 如此这般操作两年之后,我校信息办终于通过 同心云微博讨论大厅 发现了这个漏洞。但由于校际间基础设施建设仍需努力,我校决定不限期关闭 J 区 校园卡在四平路校区的使用权限。
于是,一场关于数据同步的大讨论拉开了帷幕。
诸多限制
1. 挨千刀的外包公司
由于校园一卡通相关业务开发外包给了外面的公司,且该公司总是装大爷(不提供业务源码、不进行应急响应、不积极交流意见),我校决定从管理层面入手,解决这个问题。
(纯属杜撰,我校怎么可能找这么一个外包公司开发核心业务)
2. 拉胯的传输链路
J 区 到四平路校区物理距离过远,且 J 区 网络格外差,我校为此特地打造了仅在理论上可行的 100% 电路网络。该网络每日 12 点固定分配一定带宽以支持同步操作。
因此,持续同步造成的经济损失极大(并且根本不可能(?)),每天中午 12 点进行大规模的数据同步已经是赔本赚吆喝了。
有哪些问题
倘若我们突破校园管理的极限,获得了两张相同的、都可以使用的校园卡,那么会发生什么呢?
首先声明一点,两校区数据库问题应属于 一致性(Consistency) 大类,而非单个数据库中出现的问题(如脏读、脏写、不可重复读之类的)。
1. 双写入
读书的时候,书上都拿 “一主库、多从库” / “写主库,读从库” 来举例。可我校的数据系统有两个可写入的数据库。(分布式数据系统中,应用数据私有。)
按道理来讲,如果有两个可写入的库,另一方在使用时应该多加小心,如使用 API 首先询问另一方、校验版本等等。但是现在没有这些机制。
我校通过特殊途径了解到,该外包公司并未做读写分离,所有的读写操作,均在一个数据库上实施。
2. 多主复制
根据老师描述的代码逻辑,毫无疑问我校二校区的数据同步是多主库机制(而且是模拟了长时间网络中断的多主复制)。这个机制建立在 只有一方数据得到修改 的假设之上,试图解决二库数据同时遭到修改的问题。
最终二库究竟选择哪一个数据库中的信息作为最终结果,取决于具体的业务逻辑。而这些逻辑,实现它们的码畜也会觉得自己在搞笑。
假设只有一个数据库
在我校,也只有 Mr.Tan 等少数人知道,校园卡数据被存放到了两个地方。那么对于大多数像我这种啥都不了解的学生来讲,我们不需要关心信息被放在何处,我们甚至不是时时刻刻都要确认它们是否安全,我们更想要的反而是高可用。
当然了,如果有人问到有关校内个人信息安全性的问题,我肯定是无条件地相信 —— 我的数据得到了很好的保护。
这种保护是多方面的,例如保密性(我能够轻松校验,而他人解不出来)、可用性(哪怕是大家都在查询,我也能够第一时间获取个人信息)、容灾(即使其中一个数据库宕机,还有诸多 一致性良好 的备份可以使用)。
对于我这种无条件相信一切的学生来讲,校园卡的信息仿佛就在一个地方存放着一样。
那么数据库系统完全可以利用我的这种想法,伪造 数据的确只有一个副本 的假象。
但这并不简单。
线性一致性
这个概念可以将多个数据库
实际上
该问题属于 丢失更新。
基于 J 区 极低的校内地位,我们完全可以将 J 区 数据库系统看作未提交状态,将其中所有数据看作暂存区数据,这样一来,J 区 就好似在每天中午 12 点开启了一个长达 24 小时的事务(Transaction),该事务于次日 12 点进行提交(commit)。
同校区内的,对所在校区的数据库系统的每一次写入,均视为一个 Transaction 内的操作。这些操作是 原子性 的。我们甚至可以假设它们就是 可序列化(Serializable) 的。
可现在面临以下问题:
- 每个校区拥有一套数据库系统;
- 各校区仅对所在校区数据库系统进行写入;
- J 区 与四平路校区间的数据库仅在每日 12 点同步。
因此,二校区的事务并非同一事务。二事务的操作对象——数据库系统,也并无主库从库之分。
与其说 J 区 每日 12 点进行一次数据同步,不如说 J 区 每日 12 点获取一份四平路校区的快照,在此后 24 小时内基于该快照进行写入操作。
对同一对象,在重复时间段内开启两个事务对其进行写入操作,
解决办法
1. 禁止移动
Mr.Tan 从四平路校区赶到了 J 区,才利用了漏洞。这在模型上意味着 “存在额外的信道”。
我们正常人一般只在一个校区内消费。J 区 的人一天中只会在 J 区 消费,四平路校区的人也不会故意跑出上海。按道理讲,存在的只应有 J 区学生 -> J 区 / 四平路校区学生 -> 四平路校区 两个 信道 才对。
而恰巧我们的一致性模型(如果一天同步一次也叫一致性模型的话)不能满足 多出来的信道 上的一致性。
那么我们不如禁止 Mr.Tan 的校际移动,比如停发两校区之间的班车。
存在漏洞是正常的。如果没有人能够利用它,那么它也就不会造成威胁。我校不需要防范没有威胁的漏洞。
2. 真的就一个数据库
与其花费大力气将两个数据库系统伪装成一个,不如真的只用一个数据库系统。
MAKE JIADING DISTRICT GREAT AGAIN! JIADING MATTERS!
我校应将数据库放在 J 区 与四平路校区信息办二点连线的中垂线上,比如上海交通大学。
3. 还是多主复制
多个主库就多个主库吧,没关系的。
外包公司不可能是铁板一块。我们可以买通外包公司里的一个员工,令其在规定的 996 要求之外继续加班加点干活,争取尽快开发出一个 日志系统。
该日志可以仅仅记录 一个校区内的、每个校园卡用户 的消费时间和消费金额。在每日 12 点的同步时,双数据库根据双方的日志,进行简单的合并、写入。
(注:在这里我们假设这位程序员开发出了不该存在于本宇宙的 NTPv6,一点同步延迟都没有)
诚然,Mr.Tan 仍旧可以在一天中用卡里的 100 元,消费 200 元的额度。但是到了 12 点后,卡中金额会根据真实消费情况减扣。
我们还可以对外声称,我校为校园卡配备了信用额度机制,该办法乃国内高校首创,想来定会引起全国范围内(仅限微博)的大讨论。
后记
貌似当时写到一半就莫名其妙没有继续写了……
我也忘了当时的思路,算了算了(